





Artificial intelligence has become a widely discussed technology, yet the process behind how AI systems are trained often remains unclear. Terms such as annotation, evaluation, reinforcement learning from human feedback (RLHF), and gold data frequently appear in conversations about AI development, but they rarely explain what the work actually looks like in practice.
For those who contribute to AI training through expert networks such as Deccan AI Experts, the work is far more concrete than the terminology might suggest. At its core, it involves applying human judgment to evaluate, refine, and guide the behavior of AI systems.
This article explains what that work looks like from the level of a single task to its role within the larger AI development pipeline and why individuals from a wide range of domains are essential to the process.

The Day-to-Day Work of Training AI
In practical terms, most AI training tasks involve carefully reviewing and evaluating model-generated content.
A typical workflow may involve:
- Reading a prompt, question, or piece of input content
- Reviewing one or more responses generated by an AI system
- Assessing those responses against a defined set of guidelines
The evaluation may focus on several factors, including:
- Accuracy – whether the response is factually correct
- Clarity – whether the explanation is understandable and well-structured
- Usefulness – whether the answer effectively addresses the user’s request
- Safety and compliance – whether the response follows established policies
In some cases, evaluators may compare multiple responses and determine which one better meets these criteria. In others, they may improve or rewrite a response to demonstrate what a higher-quality answer would look like.
Although each individual task may seem small, these decisions collectively create the feedback signals that shape how AI systems behave.
A single well-considered evaluation contributes to the datasets used to improve future versions of the model meaning that one human judgment can influence thousands of responses delivered to users over time.
How Human Evaluation Fits Into the AI Development Process
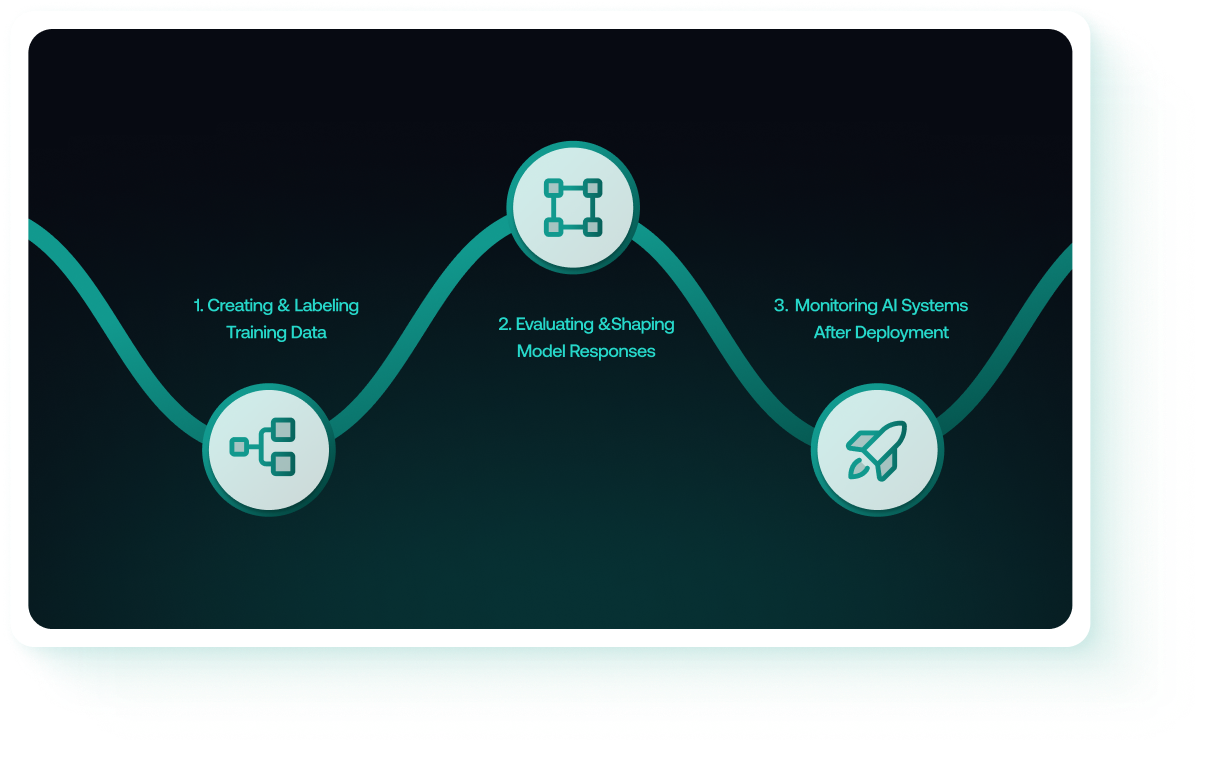
Behind most modern AI systems is a multi-stage development process that relies heavily on human input. While the specific workflows vary between organizations, the broader pipeline typically includes three core stages.
1. Creating and Labeling Training Data
AI models learn patterns by analyzing large collections of examples. These examples are drawn from real-world data sources, which may include:
- Written text such as articles, documentation, and conversations
- Images and visual media
- Audio recordings
- Structured data or logs
Before this data can be used effectively, it often requires labeling or annotation. Annotation adds meaning to otherwise unstructured information—for example:
- Identifying sentiment in a customer review
- Highlighting the portion of a document that answers a question
- Tagging objects within an image
- Marking whether a response follows specific style or policy guidelines
These labeled examples form the foundation on which models are initially trained.
2. Evaluating and Shaping Model Responses
Once a model has been trained, it can begin generating responses. However, the ability to generate text does not guarantee that the answers will be accurate, helpful, or safe.
Human evaluators play a critical role in assessing and improving these outputs.Typical evaluation tasks may involve:
- Comparing two responses to determine which one better answers a question
- Assessing the logical reasoning used by the model
- Reviewing responses to sensitive topics for safety and policy compliance
- Editing or rewriting responses to demonstrate higher-quality outputs
This feedback provides the model with signals about which types of responses should be encouraged and which should be avoided. Over time, these signals guide the model toward more reliable and useful behavior.
3. Monitoring AI Systems After Deployment
AI models are not static. Once deployed into real products and applications, they continue to evolve through updates, fine-tuning, and integration with other systems.
As a result, ongoing evaluation is necessary to ensure that the system maintains high standards of performance.
This monitoring process may involve:
- Testing new versions of a model with predefined prompts
- Checking whether previous strengths remain consistent after updates
- Identifying potential biases or unintended behaviors
- Flagging responses that are incorrect, misleading, or unsafe
Continuous oversight helps ensure that AI systems remain reliable as they are used in real-world environments.
The Importance of Diverse Expertise
One of the defining characteristics of modern AI development is the need for input from individuals with diverse professional backgrounds.
AI systems are designed to operate across many domains, and evaluating their responses requires domain-specific understanding.
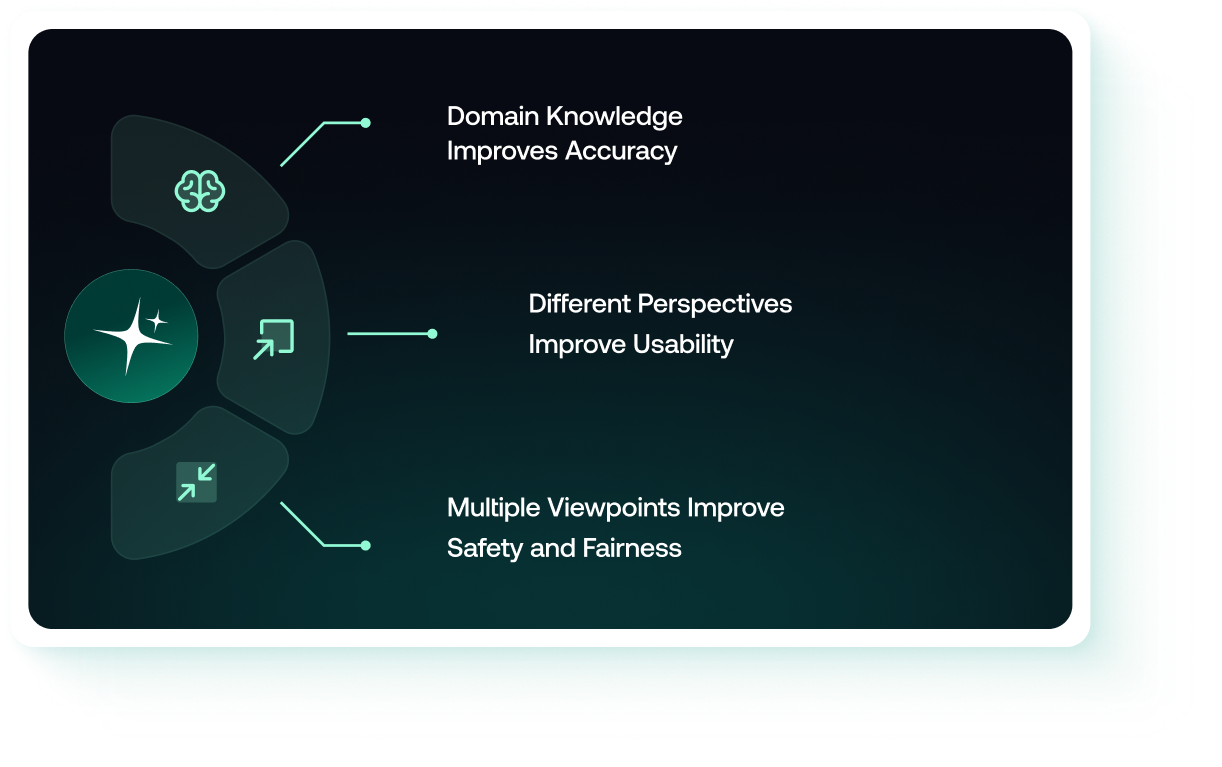
Domain Knowledge Improves Accuracy
Certain questions require specialized expertise to evaluate properly. For example:
- A medical response may appear reasonable to a general reader but could contain subtle inaccuracies that only a healthcare professional would notice.
- Legal explanations may rely on concepts that require formal training to assess correctly.
- Code generated by an AI system may function technically but still violate best practices in software engineering.
For this reason, AI evaluation projects often involve professionals with backgrounds in fields such as engineering, medicine, law, finance, and academia.
Different Perspectives Improve Usability
AI systems are used by people in a wide range of contexts, including education, business operations, customer support, and creative work.
Individuals from different professional environments bring different expectations about what makes a response useful. For example:
- Educators may emphasize clarity and structured explanations.
- Engineers may prioritize technical correctness
- Communication professionals may focus on tone and readability.
Incorporating these perspectives helps ensure that AI systems provide responses that are practical and accessible for diverse users.
Multiple Viewpoints Improve Safety and Fairness
Evaluating AI responses also requires awareness of social, cultural, and ethical considerations.
People from different cultural and professional backgrounds may identify issues that others might overlook, such as:
- Implicit bias or stereotyping
- Misinterpretation of cultural context
- Compliance risks in regulated industries
By involving evaluators with varied perspectives, AI systems can be refined to be more inclusive, responsible, and globally relevant.
The Role of Deccan AI Experts
The AI training ecosystem is rapidly expanding, with many organizations focusing primarily on large-scale data processing.
Deccan AI Experts takes a different approach. The network emphasizes:
- High-quality evaluation tasks that require careful reasoning
- Contributions from professionals with strong domain expertise
- Processes designed to capture meaningful human judgment rather than simple mechanical input
This approach reflects a broader shift in AI development: as models become more sophisticated, the value of thoughtful human evaluation continues to grow.
Participants in the Deccan AI Experts network contribute not simply by completing tasks, but by applying professional insight and critical thinking to shape how AI systems behave.



